jwacs presentation
lispvan September 2006
Hi, I'm James Wright. I'm here to talk about the jwacs project, and also about why Lisp is a good language for implementing it in. I'll make the usual disclaimer, which is please feel free to interrupt me with any questions that might occur to you during the presentation.
The story
I'm going to start with a little story about how the project came about. It all started about a year ago. I had read and heard a fair bit about continuation-based web servers (like Cocoon, Seaside, or in the Lisp world UCW) and all the advantages that they bring. The main advantage that continuations give is what UCW refers to as "Linear Page Flow Logic".
The basic idea is that the stateless nature of the HTTP protocol is one of the things that makes it a lot harder to write web applications than it really should be. Each request is an isolated event, so for operations that span multiple pages you have to store enough information that you can pick up where you left off when the next request comes in
For example, here's some code from the UCW tutorial. It's an example of adding a login page to a wiki using "regular style" (ie, no-continuation style). When a request is made for the edit.ucw page, it checks to see whether the user name is set in the current session. If it isn't, then it redirects the user to the login handler. That handler checks if the username and password parameters have been passed in and are correct; if they are, it sets the username value in the session and redirects back to the edit page; otherwise it shows a login form.
UCW and the other continuation-based web servers let you avoid a lot of that hassle by making sending a page look just like a regular function call. You call the function to send then page, and it returns when the user submits the form (or one of the forms) that the page contains. Once you can do that, your code becomes a lot more linear and cohesive. Here's the "UCW-style" (ie, with continuations) version of the same wiki example. (In both cases I've omitted the code that emits the HTML for the login form). We check the session to see whether the user name is set in the session; if not, we call the login page, which returns the username that the user logs in with.
This version matches more the way that we think about what we want to do: When a request comes in, if the user isn't logged in then handle getting them logged in and then show the edit page. It's nice and linear, it doesn't require us to decompose the problem into a state machine.
Under the covers, the that the framework accomplishes this is by saving
continuations. The answer call looks up the continuation that was
saved when the wiki-login action was called, and resumes it. This
works even though the call and the "answer" executed during two entirely
different requests. The framework hides all of those details; to the programmer
it just looks like a simple call and return.
Unfortunately, this has some scalability issues. Continuations can be kind of large[1], and you potentially have to store a new one for each page request. You can't get rid of them after the response comes back, either, because of back button, cloning, etc., so you pretty much have to resort to using timeouts to get rid of them, which has a whole other set of problems: what happens if the user walks away from the browser and comes back after the continuation has timed out? They'll have to start all over again.
Meanwhile, I was also thinking about Ajax applications. They tend to be a real pain to write.
The main reason for that is that XMLHttpRequest requests are
executed asynchronously, so you have to either write a lot of event handlers
which coordinate among each other somehow and which really obscure the control
flow; or else you have to limit yourself to extremely simple idempotent
operations that don't really have a "control flow" as such. I would claim that
Google Suggest is an
example of that sort of very simple Ajax operation.
For example, in this code, we want to display some user information, and
information about their associated institution if they have one. So we set up
an Ajax request to fetch the user data. When it comes back, the
userDataReceived handler is called, where we save the user data and
then check if the user has an institution. If they do, we set up another Ajax
request to fetch the institution data; if they don't, we just display them
without the institution data.
If we sent an institution query, then when it comes back the
institutionDataReceived event handler will be called, where we will
display the user data along with the insitution data.
You can see that handling asynchronous requests requires some pretty fragmented coding. Even this extremely contrived simple example requires two event handlers.
Well, that sounds very similar to the problem that continuations help you solve on the server side (making fragmented, asynchronous control flow seem nice and linear). So I started to wonder: What if Javascript had continuations?
- You could abstract waiting for
XMLHttpRequestresponses just like UCW abstracts waiting for page responses; - You could probably use them to get around some of the back-button issues that Ajax apps usually seem to have;
- And they wouldn't have any of the scalability problems that server-side continuations have, because every client is storing its own continuations.
So I decided to add continuation support to Javascript, and that's how I started writing jwacs.
jwacs in <some_short_amount_of_time>
Jwacs is an extended syntax for Javascript. It adds 4 new keywords to Javascript:
It also extends the syntax of the
throw statement to allow throwing
an exception into a continuation.
The user/institution Ajax code from before would look something like this in jwacs:
In this new code, we fetch the user data from the server. If the user has an associated institution, we fetch it also. Then we display the user. I think this code is a lot easier to understand than the asynchronous version.
Synchronous server requests: fetchData
Of course, I'm cheating here a bit, because I haven't shown you the
definition of the fetchData library function, which is where we
actually bust out all the new jwacs features:
Okay, turns out fetchData is just a thin wrapper over
sendRequest. It checks the status code and throws if there was any
sort of failure; otherwise it returns the raw response text.
For those of you who aren't familiar with the XMLHttpRequest,
the way it works is: You create an instance of XMLHttpRequest, set
an event handler which is called whenever the connection state changes, and then
tell it to send to an URL. The object goes away and processes the request
asynchronously, calling the event handler every so often.
So looking at sendRequest, we can see that we allocate an
XMLHttpRequest object, and then save sendRequest's
continuation into a local variable.[2] Then we set up the onreadystatechange handler,
which we'll come back to.
We open the specified url and send the request, and then we execute a
suspend statement. The suspend statement ends the
thread; sendRequest is not going to return at this point.
Meanwhile, the http request is executing, it calls
onreadystatechange a few times as it progresses, and then the
request is complete, and it calls onreadystatechange with the
"completed" state, which is 4. So we replace the handler with an empty function
and then we resume the saved continuation. At this point
sendRequest returns; the whole call stack is resurrected and
execution picks up where it left off. So it returns to fetchData,
which grabs the response text and returns to whoever called it, so in our
example it returns to userNameChanged.
If an error happens while we're querying the http object, an
exception is thrown into the saved continuation - that means that the
whole call stack is resurrected and sendRequest throws an
exception, which flies through fetchData since
fetchData doesn't have a handler, and past fetchData's
caller which may or may not catch it.
This is different from the event handler just throwing an exception as usual.
If the event handler just throws an exception, instead of throwing it into the
saved continuation, then it's the event handler's caller that the
exception is thrown to, not sendRequest's caller. Since the
event handler's caller is just the built-in browser code, that wouldn't be very
useful.
So, we can see that the library function is a little involved, but not all that hairy, and it lets us express fetches from the server in a really natural way. And of course once it's written we don't care how hairy it is anyway, we just care that we can use it and it makes our life easier.
I wanted to include a quick example of how fetchData is used in
actual running code. This is from the
Calendar demo app
on the jwacs site. The app is a simple Ajax calendar; here's what it looks
like.
You can create events by double-clicking, move them around by dragging, edit them inline, or edit them in a popup window. (in fact, you can do all of these things at once).
Here's the code that implements the interactions with the server. I've got a
fairly generic serverRequestfunction that returns the result of a
call to the server, and then a bunch of little wrapper functions like
fetchEvent for the various kinds of request.
Here's where we grab the detail data for an event that we're either editing or creating. Note that we either make an event object up, or fetch it from the server, but after we've either fetched or created it we perform pretty much the same operations on it. (Opening a child window, filling in the data, etc.) If this were written in the usual asynchronous style, everything after this point would have to be in an event handler for the editing case, although not for the new-event case; I guess there'd probably be at least two or three different functions involved depending.
Actually, calcEventEditHtml here is also using
fetchData; I probably would have written this code really
differently if I'd had to do it asynchronously.
Back-button handling: newPage
I'd like to quickly show another use for client-side continuations: Back button handling. Here's a really simple application: It shows the value of a variable, which you can increase and decrease by clicking on these links.
This is all running in the browser; there's no server interaction beyond loading up the initial page. (this app probably looks pretty familiar to those of you who were at Avi's Seaside presentation :)
Anyway, the important point to note is that the back and forward buttons work. Hurray! Let's have a look at the code.
We've got a main function that sets up the display, a debugging
function called keyCount, and the real meat of the application are
the cunningly-named click and draw functions.
The draw function just updates the display based on the current
value of the counter variable. The interesting one is the click
function, which is the onclick handler for the up and down links.
It's what changes the value of the counter. We calculate the new counter value,
and then we call newPage, which just notes that we are about to
draw a new page which should get a new history entry. And then we set the
counter and draw the new page.
The way this works is that newPage adds a unique hash to the
current URI, and then stores its continuation in a map using that unique hash as
a key, and then returns. When we go back in the history to that URI, that
continuation is resumed. So let's say we click up and the counter's value goes
to 1; we click a few more links, doesn't really matter which ones, and then we
hit the back button to get back to 1.
The continuation that newPage stored is resumed, so we return
from this newPage call with all of our locals and return addresses
and whatnot restored; we set the counter to the newVal that we had
calculated before we called newVal; and we draw the new value.
This is an example of where it's helpful to resume the same continuation more
than once. newPage returns normally the first time; then it
returns again every single time we go back to this point in the history.
This is again obviously a pretty contrived example, because there's only one piece of state in this app, so why not just put that in the URI instead of messing around with continuations. But in more complex apps where you have a lot of state it might save you from having to marshal and unmarshal the whole world.
The Guts
I'm going to talk now a little bit about how jwacs works.Usage
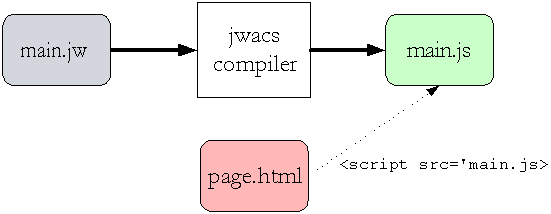
In terms of usage, what the programmer does is write a bunch of code in the extended syntax with the new keywords that I was describing before. That code is used as input to the jwacs compiler, which spits out a standard Javascript file that can be pointed to by an html file.
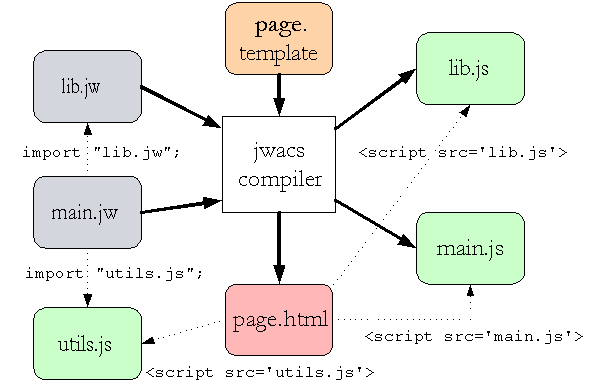
It's not usually that simple, of course. A jwacs file can import other jwacs files or plain Javascript files, you can give the jwacs compiler a simple template and it'll generate the html file for you, there's different compression and combination options, etc. But for now let's just worry about the simple case.
CPS transformation
So what does the compiler actually do to get from the extended syntax to the regular syntax? What transformations does it perform to add continuation support? Well, there's actually a whole pipeline of transformations that happen, but the most important one is the CPS transformation[3]. CPS stands for "continuation passing style"; basically, a function that is in continuation passing style accepts a continuation function as an argument, which it calls whenever it wants to return.
Here's a very simple example of a CPS transformation. The original, "direct
style" version of the foo function calls bar, assigns
its return value to x, and then passes x to
baz and returns the result.
When we CPS-transform this code, here's what we get. Notice that
foo now takes an extra argument called $k; that's the
continuation argument that we need to call when we return. We still call
bar, but now we're passing this extra anonymous function; that
anonymous function will be bar's continuation. The anonymous
function takes an argument named x, so when bar
returns by calling this continuation the return value that it passes to the
continuation will be assigned to x while the continuation is
executing.
Inside the continuation we have all the code that used to come after the call
to bar in foo; in this case, that's just a call to
baz followed by the return statement. The new, transformed call to
baz also takes a continuation argument, of course, which contains
everything in the function that followed the call to baz; in this
case, that's just the return statement. The return statement has been
transformed into a tail-call to foo's continuation $k.
So basically, this new code has exactly the same effect as the old code did, except that now all of the continuations have been made explicit. The new keywords just transform into Javascript that operates on these continuations.
For example, suspend just turns into a return
statement that doesn't call the current continuation and resume
just turns into a return that calls the specified continuation instead of the
current continuation. function_continuation just turns into a
reference to the continuation parameter of the current function, which it turns
out is always named $k. And return just turns into a
tail call to the current function's continuation.
This is actually a big simplification. We're making all these extra function calls when we return, so what about stack issues? How do we deal with function calls that take other function calls as their arguments? What if we need to call a direct-style function (like any of the built-in ones) from transformed code? What if those direct-style functions need to call cps-style functions?
Well, I'm not going to go into any of that. But I just thought I'd mention that I do deal with those cases. :)
Lisp benefits
I'd like to point out a few of the areas where using Lisp was a big advantage for me.
parsing: DSLs and restarts
The first area was in parsing. Thanks to Lisp's ability to easily create
domain-specific languages, I'm able to embed a declarative parser grammar right
in the code, which will then be transformed by a macro into a state-machine
parser. I'm using cl-yacc to do this
conversion. The grammar definition is just a list of s-expressions, each one representing
a production. So for example this production here says that a
primary-expression can be a left-parenthesis followed by an
expression followed by a right-parenthesis.
In almost any other language, you'd have to either resort to a seperate code-generator like bison or antlr, or hand-code your own recursive-descent parser. In Lisp, I was able to just transcribe the grammar from the spec[4] and I was ready to go.
Lisp's error handling was an even bigger advantage, because it turns out that just implementing the grammar from the Javascript standard doesn't actually give you a standards-compliant parser. Javascript has this notion of "automatic semicolon insertion". The spec says: "Parse according to this grammar. Then, if you happen encounter an error, and there was a line terminator before the "offending token", then you must try inserting a semicolon and see if that fixes the error.
I read that and thought to myself, "You have got to be kidding me."
But in fact, it was relatively straightforward to implement in Lisp, because of
restarts. When the parser signals an error, I just check whether the lexer
encountered a line terminator before the current token (or the other cases where
you have to insert a semicolon); if so, I invoke an INSERT-TERMINAL
restart with a semicolon as the argument, and carry on parsing. The restart is
invoked without unwindind the stack, so the parser is able to carry on because
it hasn't lost any state.
source transformations and pretty-printing: generic functions with multiple dispatch
Another big advantage that Lisp has is multiple-dispatch methods. I
basically have a single generic function named transform that I
apply to a parse tree to create a new parse tree. The basic overview of how
jwacs works is:
- read jwacs source
- parse it into a parse tree
- transform the parse tree to put all the functions into continuation-passing style, which gives us a new parse tree
- and then pretty-print the new parse tree to produce the javascript output
But to implement each of these source transformations, I just write a bunch of methods that specialize on both the transformation-type (shift-decls, CPS, or whatever), as well as on the type of source-element that I'm transforming.
Each transform method returns a transformed version of its
source element argument. For elements that contain other elements (eg function
declarations, which contain statements), the transform method recursively calls
itself on the child elements to build the transformed sub-elements.
As an example, this is a method in the shadow-values
transformation, which replaces references to the special arguments
variable with references to another special variable. If arguments
is currently shadowed, and the identifier argument that has been passed into
transform has a name of arguments, then replace it
with a new identifier with the new name. Otherwise we just call the default
method (which will just return an unchanged copy of the identifier).
This is essentially the Visitor pattern. However, unlike in Java, we didn't have to implement any of the plumbing of elements accepting a visitor and then immediately turning around and calling the appropriate visitor method. There's 45 different source element types in the parse tree, so that's a pretty substantial reduction in boilerplate code.
source transformations: special variables
The other thing to note in this code is that I'm using a special variable called*shadowed-arguments-name* to indicate whether this part of the code
should be using a shadowed name. The glorious thing about special variables
when you're walking a source tree is that the dynamic scope of the source-walker
mirrors the lexical scope of the source tree that you're walking.
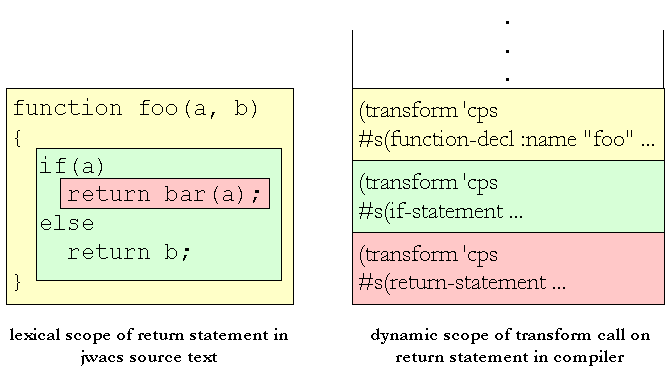
So for example, if you are processing an identifier that is in an
if-statement that is in the foo function, then the
transform call for the if statement will be on the stack, and
further up the transform call for the function declaration will be
there too. So tracking stuff like what variables are in lexical scope for the
element that is being processed or what the current function is is pretty
straightforward; you just bind a special variable in the compiler when things
come into lexical scope as you walk the source, and it will automatically be
unbound when they scope out, because you'll also be leaving the function that
processes the element that created the scope.
Summary
So, to sum up:
Thanks!
Footnotes
[1] UCW requires roughly 400 bytes of memory per session plus 700 bytes per request/response iteration according to Marco Barringer.[2] We're saving it instead of just
using it directly, because we want to use it in the
onreadystatechange handler; but if we reference
function_continuation in the handler, we'll get the handler's
continuation instead of sendRequest's.
[3] See, for example, the Wikipedia article on Continuation-passing style.
[4] ECMA-262, available at http://www.ecma-international.org/publications/standards/Ecma-262.htm